
DigitalOcean + Weaviate
DigitalOcean's Serverless Inference hosts a curated set of open-weight embedding and language models behind a single OpenAI-compatible API. Weaviate integrates with DigitalOcean's embedding endpoint so you can vectorize and search data using DigitalOcean-hosted models directly from your Weaviate instance.
Looking to host Weaviate on DigitalOcean? See DigitalOcean Managed Weaviate.
Integrations with DigitalOcean
Embedding models for vector search
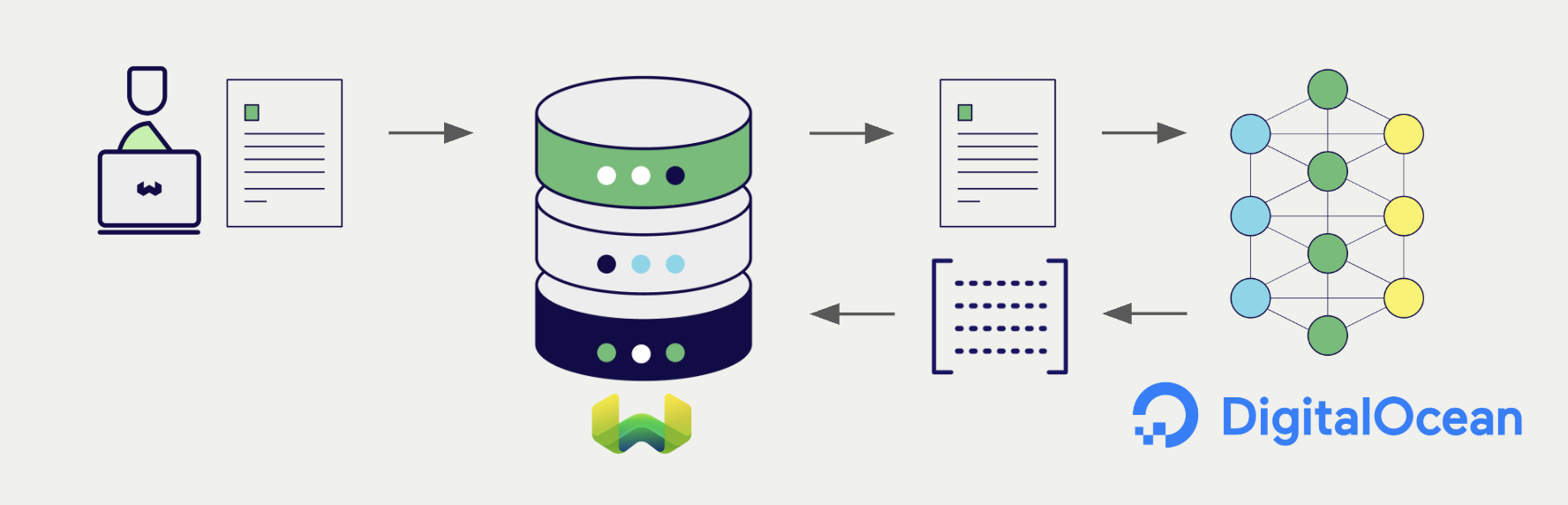
DigitalOcean Serverless Inference exposes embedding models (e.g. qwen3-embedding-0.6b) over an OpenAI-compatible /v1/embeddings API at https://inference.do-ai.run.
Weaviate integrates with DigitalOcean's embedding models through the text2vec-digitalocean vectorizer module. Configure a vector index to use a DigitalOcean model and Weaviate generates embeddings for imports, vector searches, and hybrid searches automatically.
DigitalOcean embedding integration page
Summary
This integration lets you leverage DigitalOcean's hosted embedding models from Weaviate without managing inference infrastructure yourself.
Get started
Generate an API key in the DigitalOcean Cloud console and supply it to Weaviate via the DIGITALOCEAN_APIKEY environment variable or the X-Digitalocean-Api-Key request header. Then see the embedding integration page:
Questions and feedback
Have a question or feedback? Here's how to reach us.