
Cohere Multimodal Embeddings with Weaviate
Weaviate's integration with Cohere's APIs allows you to access their models' capabilities directly from Weaviate.
Configure a Weaviate vector index to use a Cohere embedding model, and Weaviate will generate embeddings for various operations using the specified model and your Cohere API key. This feature is called the vectorizer.
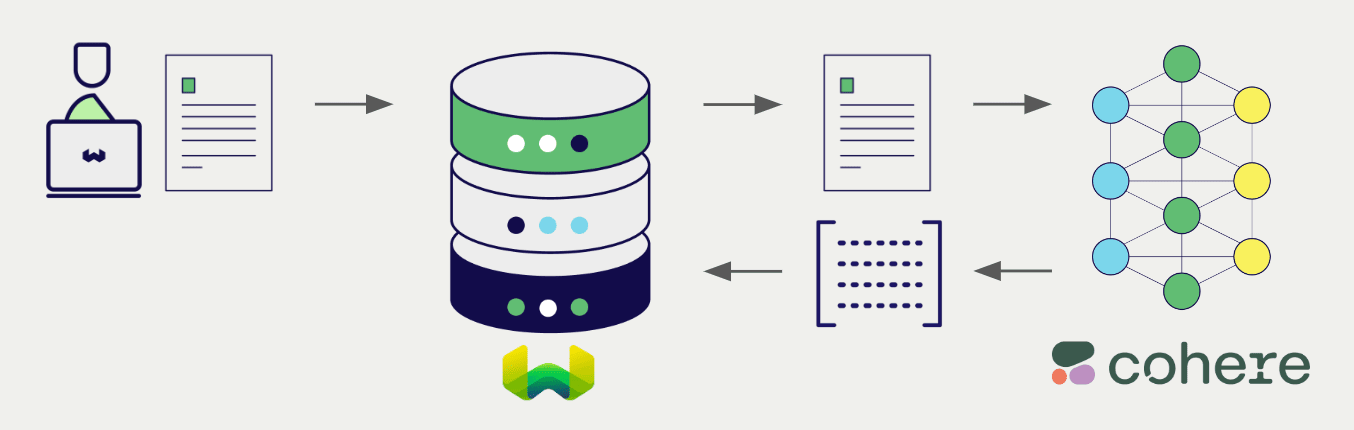
At import time, Weaviate generates multimodal object embeddings and saves them into the index. For vector and hybrid search operations, Weaviate converts text queries into embeddings. Multimodal search operations are also supported.
Requirements
Weaviate configuration
Your Weaviate instance must be configured with the Cohere vectorizer integration (multi2vec-cohere) module.
For Weaviate Cloud (WCD) users
This integration is enabled by default on Weaviate Cloud (WCD) instances.
For self-hosted users
- Check the cluster metadata to verify if the module is enabled.
- Follow the how-to configure modules guide to enable the module in Weaviate.
API credentials
You must provide a valid Cohere API key to Weaviate for this integration. Go to Cohere to sign up and obtain an API key.
Provide the API key to Weaviate using one of the following methods:
- Set the
COHERE_API_KEYenvironment variable that is available to Weaviate. - Provide the API key at runtime, as shown in the examples below.
If a snippet doesn't work or you have feedback, please open a GitHub issue.
import weaviate
from weaviate.classes.init import Auth
import os
# Recommended: save sensitive data as environment variables
cohere_key = os.getenv("COHERE_API_KEY")
headers = {
"X-Cohere-Api-Key": cohere_key,
}
client = weaviate.connect_to_weaviate_cloud(
cluster_url=weaviate_url, # `weaviate_url`: your Weaviate URL
auth_credentials=Auth.api_key(weaviate_key), # `weaviate_key`: your Weaviate API key
headers=headers
)
# Work with Weaviate
client.close()
Configure the vectorizer
Configure a Weaviate index as follows to use a Cohere embedding model:
If a snippet doesn't work or you have feedback, please open a GitHub issue.
from weaviate.classes.config import Configure, DataType, Multi2VecField, Property
client.collections.create(
"DemoCollection",
properties=[
Property(name="title", data_type=DataType.TEXT),
Property(name="poster", data_type=DataType.BLOB),
],
vector_config=[
Configure.Vectors.multi2vec_cohere(
name="title_vector",
# Define the fields to be used for the vectorization - using image_fields, text_fields
image_fields=[
Multi2VecField(name="poster", weight=0.9)
],
text_fields=[
Multi2VecField(name="title", weight=0.1)
],
)
],
# Additional parameters not shown
)
Select a model
You can specify one of the available models for the vectorizer to use, as shown in the following configuration example.
If a snippet doesn't work or you have feedback, please open a GitHub issue.
from weaviate.classes.config import Configure, DataType, Multi2VecField, Property
client.collections.create(
"DemoCollection",
properties=[
Property(name="title", data_type=DataType.TEXT),
Property(name="poster", data_type=DataType.BLOB),
],
vector_config=[
Configure.Vectors.multi2vec_cohere(
name="title_vector",
model="embed-v4.0",
dimensions=1024,
# Define the fields to be used for the vectorization - using image_fields, text_fields
image_fields=[
Multi2VecField(name="poster", weight=0.9)
],
text_fields=[
Multi2VecField(name="title", weight=0.1)
],
)
],
# Additional parameters not shown
)
You can specify one of the available models for Weaviate to use. The default model is used if no model is specified.
Vectorization behavior
Weaviate follows the collection configuration and a set of predetermined rules to vectorize objects.
Unless specified otherwise in the collection definition, the default behavior is to:
- Only vectorize properties that use the
textortext[]data type (unless skipped) - Sort properties in alphabetical (a-z) order before concatenating values
- If
vectorizePropertyNameistrue(falseby default) prepend the property name to each property value - Join the (prepended) property values with spaces
- Prepend the class name (unless
vectorizeClassNameisfalse) - Convert the produced string to lowercase
Vectorizer parameters
The following examples show how to configure Cohere-specific options.
If a snippet doesn't work or you have feedback, please open a GitHub issue.
from weaviate.classes.config import Configure, DataType, Multi2VecField, Property
client.collections.create(
"DemoCollection",
properties=[
Property(name="title", data_type=DataType.TEXT),
Property(name="poster", data_type=DataType.BLOB),
],
vector_config=[
Configure.Vectors.multi2vec_cohere(
name="title_vector",
# Define the fields to be used for the vectorization - using image_fields, text_fields
image_fields=[
Multi2VecField(name="poster", weight=0.9)
],
text_fields=[
Multi2VecField(name="title", weight=0.1)
],
# Further options
# model="embed-v4.0",
# dimensions=1024,
# truncate="END", # "NONE", "START" or "END"
# base_url="<custom_cohere_url>"
)
],
# Additional parameters not shown
)
For further details on model parameters, see the Cohere API documentation.
Data import
After configuring the vectorizer, import data into Weaviate. Weaviate generates embeddings for image objects using the specified model.
If a snippet doesn't work or you have feedback, please open a GitHub issue.
collection = client.collections.use("DemoCollection")
with collection.batch.fixed_size(batch_size=200) as batch:
for src_obj in source_objects:
poster_b64 = url_to_base64(src_obj["poster_path"])
weaviate_obj = {
"title": src_obj["title"],
"poster": poster_b64 # Add the image in base64 encoding
}
# The model provider integration will automatically vectorize the object
batch.add_object(
properties=weaviate_obj,
# vector=vector # Optionally provide a pre-obtained vector
)
If you already have a compatible model vector available, you can provide it directly to Weaviate. This can be useful if you have already generated embeddings using the same model and want to use them in Weaviate, such as when migrating data from another system.
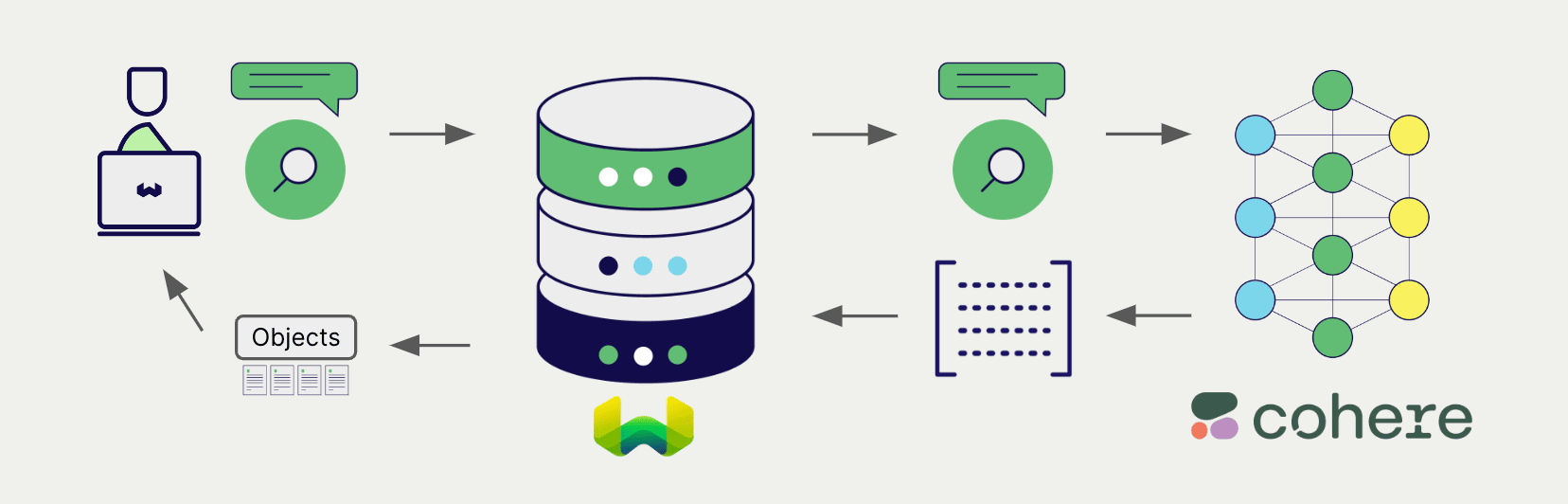
Searches
Once the vectorizer is configured, Weaviate will perform vector and hybrid search operations using the specified Cohere model.
Vector (near text) search
When you perform a vector search, Weaviate converts the text query into an embedding using the specified model and returns the most similar objects from the database.
The query below returns the n most similar objects from the database, set by limit.
If a snippet doesn't work or you have feedback, please open a GitHub issue.
collection = client.collections.use("DemoCollection")
response = collection.query.near_text(
query="A holiday film", # The model provider integration will automatically vectorize the query
limit=2
)
for obj in response.objects:
print(obj.properties["title"])
Hybrid search
A hybrid search performs a vector search and a keyword (BM25) search, before combining the results to return the best matching objects from the database.
When you perform a hybrid search, Weaviate converts the text query into an embedding using the specified model and returns the best scoring objects from the database.
The query below returns the n best scoring objects from the database, set by limit.
If a snippet doesn't work or you have feedback, please open a GitHub issue.
collection = client.collections.use("DemoCollection")
response = collection.query.hybrid(
query="A holiday film", # The model provider integration will automatically vectorize the query
limit=2
)
for obj in response.objects:
print(obj.properties["title"])
Vector (near media) search
When you perform a media search such as a near image search, Weaviate converts the query into an embedding using the specified model and returns the most similar objects from the database.
To perform a near media search such as near image search, convert the media query into a base64 string and pass it to the search query.
The query below returns the n most similar objects to the input image from the database, set by limit.
If a snippet doesn't work or you have feedback, please open a GitHub issue.
def url_to_base64(url):
import requests
import base64
image_response = requests.get(url)
content = image_response.content
return base64.b64encode(content).decode("utf-8")
collection = client.collections.use("DemoCollection")
query_b64 = url_to_base64(src_img_path)
response = collection.query.near_image(
near_image=query_b64,
limit=2,
return_properties=["title", "release_date", "tmdb_id", "poster"] # To include the poster property in the response (`blob` properties are not returned by default)
)
for obj in response.objects:
print(obj.properties["title"])
References
Available models
embed-multilingual-v3.0(Default)embed-multilingual-light-v3.0embed-english-v3.0embed-english-light-v3.0
Further resources
Other integrations
- Cohere text embedding models + Weaviate.
- Cohere generative models + Weaviate.
- Cohere reranker models + Weaviate.
Code examples
Once the integrations are configured at the collection, the data management and search operations in Weaviate work identically to any other collection. See the following model-agnostic examples:
- The How-to: Manage collections and How-to: Manage objects guides show how to perform data operations (i.e. create, read, update, delete collections and objects within them).
- The How-to: Query & Search guides show how to perform search operations (i.e. vector, keyword, hybrid) as well as retrieval augmented generation.
External resources
- Cohere Embed API documentation
Questions and feedback
Have a question or feedback? Here's how to reach us.